
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Codebuild
- DevOps
- ingress
- SSL Offload
- Codepipeline
- emptyDir Volume
- node exporter
- RKE2
- emptyDir
- pod
- cicd
- AWS
- slack
- Persistent Volume
- aws-dop
- kubernetes
- ingress controller
- HTTPS Redirect
- ALB
- Naver cloud platform
- codecommit
- volume
- Prometheus
- grafana
- alertmanager
- k8s
- NFS Client Privisioner
- ncp
- Codedeploy
- Persistent Volume Claim
- Today
- Total
Cloud SA's This and That
[NCP] - Cloud Hadoop(2) Spark, Hue&Hive 활용 테스트 본문
앞서 NCP에서 생성한 Cloud Hadoop 클러스터를 기반으로
(1) Spark를 활용한 work count 테스트 및 (2) Hu&Hive를 활용한 csv 데이터 분석 테스트를 진행해보았다.
[Spark를 활용한 word count]
1. ssh로 클러스터 접속

> ssh 접속을 위해 22번 포트 오픈

IP : 클러스터 도메인(콘솔에서 확인 가능) / user : sshuser / 인증키(.pem) 사용

> 엣지 노드에 접속됨
[Text.txt]

2. Test 데이터를 Hadoop으로 이동 (hadoop 명령어 참고: https://givitallugot.github.io/articles/2021-08/Hadoop-engineering-fs)

> hadoop fs -mkdir [디렉터리] : HDFS에 새로운 디렉토리 생성
> hadoop fs -ls [경로] : 해당 경로 파일 확인

> HDFS의 /user/sshuser 디렉터리 확인

> 로컬의 test.txt 파일을 hadoop의 /user/sshuser/로 복사
3. spark를 활용한 word count 실행
우선 spark-shell을 실행

Word count 코드 작성

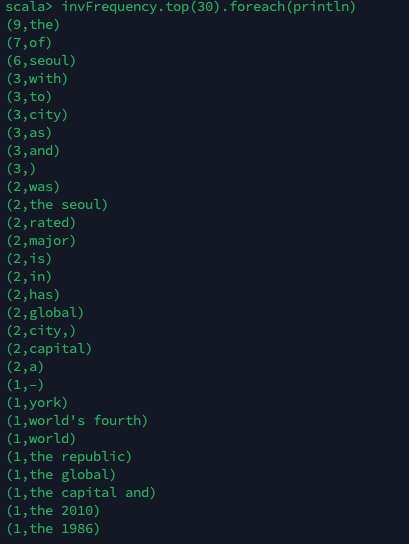
Cloud Hadoop을 사용하면 정형화된 데이터뿐만 아니라 긴 텍스트 데이터들도 용이하게 분석 가능하다.
========================================================================================
[Hue & Hive를 활용한 csv 데이터 분석]
1. csv 데이터를 Object Storage에 업로드

> 클러스터 생성 시 설정한 Object Storage에 새폴더(test1) 생성 후 해당 폴더에 csv 파일 업로드
<간단하게 다시 테스트해보기로 함>

> 해당 엑셀파일을 csv 형태로 저장하여 Object Storage에 업로드
2. Hue 접속 후 데이터 분석

> 콘솔에서 클러스터 선택 후 상단의 "Application별 보기" 클릭 -> Hue Admin 접속용 클릭 -> 접속
> 이때에도 acg 설정 8081포트 열려있어야 함

>로그인은 클러스터 생성시 입력했던 클러스터 관리자 계정 및 패스워드 입력

> Hive 편집기 화면
> Hive : SQL과 같은 쿼리 언어를 Hadoop에서 실행하기 위한 소프트웨어 (MapReduce는 Java언어를 사용 - 프로그래머가 아닌 이상 사용하기 어려움)

> 쿼리문 작성
> LOCATION : 데이터셋 파일이 저장된 버킷 경로
> 쿼리문 실행 후 success 확인

> Hive에 Object Storage의 데이터 연동 확인됨
위와 같이 쿼리문을 사용하여 원하는 데이터를 추출(select...from..where 등)할 수 있으며 새로운 데이터를 붙일 수도(insert into..values... 등) 있다.

> 쿼리 결과를 차트를 통해서도 확인이 가능하다.
'Naver-Cloud > Big Data' 카테고리의 다른 글
| [NCP] - Cloud Hadoop(1) 서비스 소개 및 클러스터 생성 (0) | 2023.07.24 |
|---|
