
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- aws-dop
- volume
- codecommit
- slack
- RKE2
- ingress
- grafana
- emptyDir Volume
- Codepipeline
- Codedeploy
- Persistent Volume
- DevOps
- Codebuild
- HTTPS Redirect
- cicd
- ALB
- node exporter
- AWS
- ncp
- pod
- Naver cloud platform
- Prometheus
- NFS Client Privisioner
- kubernetes
- SSL Offload
- ingress controller
- emptyDir
- alertmanager
- Persistent Volume Claim
- k8s
- Today
- Total
Cloud SA's This and That
[NCP] - Cloud Hadoop(1) 서비스 소개 및 클러스터 생성 본문
* Hadoop ecosystem에 대한 내용은 Big Data 카테고리에 따로 업로드 예정입니다.
[Cloud Hadoop] - 빅데이터를 쉽고 빠르게 처리할 수 있는 오픈소스 기반의 분석 서비스
- 사용 편의성 : 완전 관리형으로 자동으로 클러스터 생성을 지원하여 인프라 관리 작업에 대한 부담이 적음
- 비용 효율성 : 데이터 저장소로 네이버 클라우드 플랫폼의 Object Storage를 사용해 저렴한 비용으로 대량 데이터 저장 / 클러스터가 시작된 시점부터 종료될때까지 사용한 만큼만 지불
- 유연한 확장성 및 안정성 : 사용자 원하는 시간에 데이터분석에 필요한 인스턴스의 수를 손쉽게 줄이거나 늘릴 수 있음 / 마스터 노드(NameNode)를 2개로 제공
- 관리 및 모니터링을 위한 web UI 제공 : 클러스터에 대한 루트 접근 권한을 제공하므로 클러스터를 완벽하게 제어할 수 있으며 프레임워크의 설정값을 확인 및 수정이 가능함
- 다양한 프레임워크 지원 : apache, hadoop, 대용량 저장소 HBase, 데이터 웨어하우스 소프트웨어인 Hive, 대규모 데이터 처리용 엔진 Spark 등을 지원함
[NCP 빅데이터 서비스]


>Data Forest 서비스를 사용하면 데이터 처리부터 시각화까지 한번에 빅데이터 서비스 사용 가능

>보안에 필수적인 Ranger나 Kerberos 또한 제공하고 있다.
[Cloud Hadoop Architecure]

> 외부접속을 위한 Edge Node를 제공하여 클러스터 접근 보안성을 높이고 있다.(gateway 역할)
> 클라이언트는 Hadoop Cluster에 접근하기 위해서는 Edge Node에 접속해야 하며 이때 SSL VPN을 통해서 접근이 가능하다.
-> Edge Node 안에서 하둡 클러스터 내의 노드에 SSH로 접근이 가능하다.
> 2대의 Master Node가 기본으로 제공되며 Edge Node와 Master Node의 갯수는 수정이 불가하다.
> Worker node는 최소 2대부터 최대 8대까지 생성이 가능하다. / 이후 동적으로 노드 추가,삭제 가능
> 각 노드의 스토리지 용량은 100GB~2000GB 혹은 4000GB, 6000GB로 생성이 가능하다.

>Object Storage - 클러스터를 생성하기 전에 데이터를 저장하고 검색하기 위한 Object Storage 버킷이 생성되어 있어야 한다.
기능 : 데이터 무결성 및 복원력 보장 / 초대용량 데이터 저장 가능 (GB~PB) / 외부 도구 호환 가능 ( NCP 콘솔, RESTful API, Amazon S3 ) / 우수한 데이터 검색 (데이터 저장 시 고유 식별자와 메타데이터 부여) / 데이터 수명 주기별 적합한 스토리지 사용 가능
>Cloud Hadoop 클러스터의 Hue 지원기능 : 브라우저(문서,파일,S3,테이블,Job) / 편집기(Hive, Scala, PySpark, Submit Jar, Spark, Java, Distcp, Shell, MapReduce) / 스테줄러(Workflow, 예약)
[Reference Architecture]
<Batch Job Architecutre>

>fluentd를 통해 로그를 Object Storage에 저장할 수 있으며 이미지 데이터베이스 혹은 완전관리형 데이터베이스를 통해
데이터들을 하둡 클러스트를 통해 데이터웨어하우스에 적재할 수 있다.
<Real Time Architecture>

>실시간 이벤트 로그들이 Kafka를 거치게 되며 이러한 Kafka는 클라우드 데이터 스트리밍 서비스를 활용할 수도 있다.
>하둡 클러스터에서 HDFS를 활용하거나 Object Storage에 적재를 한 후에는 Batch Job과 비슷한 적재 후 다양한 형태로 데이터마트나 대쉬보드 등을 활용할 수 있다.
<Data Pipeline Architecture>

> 데이터 스트리밍 서비스 큐에 쌓은 데이터들을 Spark를 통해서 ETL 작업을 한 후에 Object Storage로 넘겨주고
> Object Storage의 데이터들을 Hive와 Presto를 통해 쿼리 방식으로 처리 가능하며 이러한 Workflow Management Tool로는 OOZiE나 Airflow를 사용할 수 있다.

> 다양한 프로듀서 애플리케이션들이 다양한 토픽에 Publishing하며 토픽의 데이터들을 Consumer들이 polling
> ncp에서도 클러스터 형태로 Hadoop과 ElasticSearch를 구성 가능하며 이러한 서비스들이 각각의 Consumer가 되어 Object Storage에도 데이터를 쌓을 수있다.
> ElasticSearch를 통해 Kibana로 시각화하거나 Hadoop으로 병렬 처리를하여 원하는 후속 작업이 가능하다.
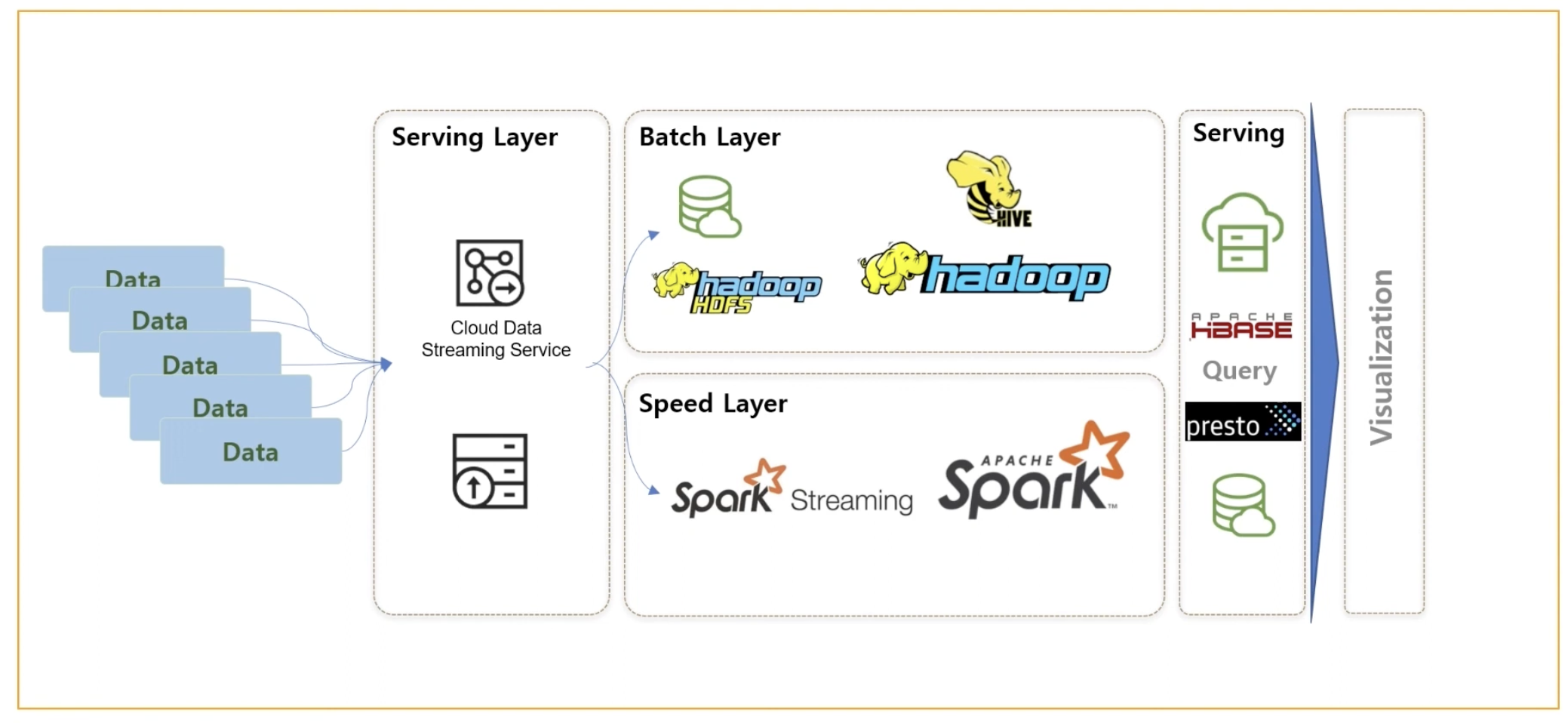
> Cloud Data 스트리밍 서비스를 사용하여 데이터들을 메시지 큐에 담아 배치작업이나 Spark Streaming과 같은 실시간 처리엔진을 통해 처리 가능
> 처리한 데이터들을 presto나 HBase, Object Storage 등에 처리한 후 시각화 가능
========================================================================================
[Cloud Hadoop 클러스터 생성]
<<Cloud Hadoop 사용 환경>>
1. VPC
- 클러스터의 개수와 상관없이 최소 1개의 vpc 필요
- 여러 개의 클러스터를 같은 vpc에 두고 사용 가능
2. Subnet
- Cloud Hadoop 생성 시 퍼블릭 서브넷과 프라이빗 서브넷을 노드 용도에 맞게 생성하고 사용할 수 있다.
- 엣지 노드, 마스터 노드 : 퍼블릭 or 프라이빗 서브넷 / 작업자 노드 : 프라이빗 서브넷
3. Region
- 리전이 사용자와 가까울수록 서버 응답 속도가 빠르므로 사용자와 리전의 물리적 거리를 고려해 리전 선택
<<클러스터 생성>>
1. Object Storage 생성 (클러스터를 생성하기 전에 데이터를 저장하고 검색하기 위한 Object Storage 버킷이 생성되어 있어야 한다)

2. VPC , Subnet 생성
- VPC : 10.0.0.0/16
- Subnet : Public 2개, Private 1개

3. 클러스터 생성
<클러스터 설정>

> 클러스터 버전 : 현재 Cloud Hadoop 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2.0 제공 중
> 클러스터 Type : 클러스터를 구성한 application 선택
> 클러스터 add-on : 추가로 필요한 컴포넌트 선택 가능
> Data Catalog 사용 : Cloud Hadoop 하이브 메타스토어를 Data Catalog 서비스의 카탈로그를 사용하여 제공 (Data Catalog 서비스의 카탈로그 상태가 정상 중일 경우에만)
> 커버로스 인증 구성 : Kerberos를 사용하여 Secure Hadoop 클러스터를 구성하려고 하는 경우에 선택(Realm : 인증관리도메인 - KDC admin / KDC 관리자 계정 패스워드)
> 클러스터 관리자 계정 : Ambari 관리 콘솔에 접속하기 위한 클러스터 계정 설정
> ACG 설정 : Cloud Hadoop ACG는 클러스터 생성 시에 자동 생성됨
<스토리지 & 서버 설정>

> Object Storage : Cloud Hadoop 클러스터는 사전 작업 시 생성한 오브젝트 스토리지 버킷에서 데이터를 읽고 쓸 수 있다. 잠금이 설정된 버킷은 Cloud Hadoop과 연동되지 않는다.
> Bootstrap Script : Cloud Hadoop과 연동되어 오브젝트 스토리지 버킷에 업로드한 쉘스크립트를 Cloud Hadoop 생성 시점에 실행해주는 기능
> 고가용성 지원 : Cloud Hadoop은 기본적으로 HDFS NameNode, YARN Resource Manager, Oozie Server, HiveServer에 대한 이중화를 제공 ( 선택 해제 불가 )
> 작업자 노드 개수 : 작업자 노드 개수는 2~8개까지 선택할 수 있으며 클러스터 생성 이후에도 추가 또는 삭제가 가능하다.



>클러스터 생성은 30~50분정도 소요된다.
<요금 >
- 요금은 클러스터가 시작된 시점부터 종료까지 사용자가 사용한 만큼 지불하는 방식 - (인스턴스 + Block Storage + Object Storage + 네트워크 전송 )
- 마스터 노드는 기본적으로 2대가 생성되며 기본 제공되는 50GB 디스크는 별도로 증설이나 추가되지 않으며 이용요금에 포함되어 있다.
- 데이터 스토리지 요금(Block Storage)는 Cloud Hadoop HDFS 데이터를 저장하기 위한 스토리지로 최고 100GB~2000GB까지 10GB 단위로 사용가능하고 4000, 6000GB 사용 가능하다.
- 데이터 저장량 요금(Object Storage)는 대용량의 데이터를 저장하기 위한 스토리지로 저장된 데이터 양, API 요청 수, 네트워크 전송요금을 합산하여 부과된다.
- 네트워크 전송요금은 아웃바운드 트래픽에 대한 네트워크 사용량에 따라 과금된다.
[클러스터 관리]
<backup>
- 클러스터 설정 백업은 콘솔을 통해 쉽게 가능하며 백업파일은 클러스터와 연동된 Object Storage 버킷 하위에 저장된다.

> 클러스터 설정 백업 클릭 (메인계정에서만 백업이 가능)
<클러스터 worker node 추가>
- 클러스터 작업자 노드에 비해 자원이 부족할 경우 작업자 노드 수를 조정하여 해결가능 하다.

> 클러스터 노드 수 변경 클릭

> 노드 수 3으로 변경

'Naver-Cloud > Big Data' 카테고리의 다른 글
| [NCP] - Cloud Hadoop(2) Spark, Hue&Hive 활용 테스트 (1) | 2023.07.25 |
|---|
